
Generative AI moves like a runaway train. “I’ll catch up this weekend” is a lie we tell ourselves between experiments, code reviews, and reviewer 2.
🛠️ The fix: stop doom-scrolling and make an LLM Paper Radar that hunts for new papers and drops a tidy digest in your inbox every Monday and Thursday morning.
We’ll use n8n Cloud — a hosted, no-ops automation canvas that lets you wire APIs together like LEGO. No servers, no yak-shaving. If you want to self-host n8n via Docker or npm, cool — but we are focusing on n8n Cloud because the GPU cluster already eats up enough of my time.
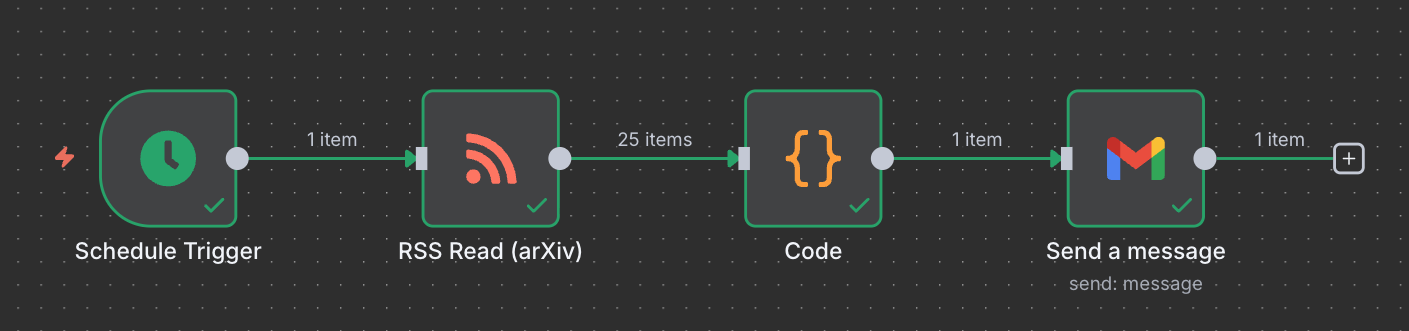
Here’s the game plan: Schedule → arXiv → Code (filter/score/HTML) → Gmail.
No API key required for arXiv. If you have a Semantic Scholar API key, you can bolt it on later for citations and open-access links.
What n8n Cloud gives you (and why I use it)
✔️ A clean visual canvas: drag nodes, connect arrows, hit run.
✔️ Built-in nodes for Gmail, HTTP, Code execution, schedulers, and more.
✔️ Hosted. It just runs. You focus on research, not uptime.
If you’re allergic to SaaS, n8n also runs locally (npm i -g n8n, or Docker). Same workflow, same nodes.
The system — in one picture
→ Schedule (Mon & Thu, 07:30)
→ RSS Read (arXiv) with a query tuned for Generative AI & LLM topics (and optionally RAG, Agentic RAG, AI Agents, Multi-Agent).
→ Code node: filter noise, score, pick top 5, format pretty HTML.
→ Gmail: send to your inbox.
That’s it. Two emails a week. Zero FOMO.
Step 1. Add Schedule Trigger
- Search in the node menu: Schedule Trigger.
- Configure it to run on Monday and Thursday at 07:30 (Helsinki time).
– Weekday = 1 (Monday), time = 07:30
– Weekday = 4 (Thursday), time = 07:30
This ensures the whole workflow only fires twice a week.
Step 2. Add RSS Feed Read (arXiv)
- Search for RSS Feed Read node.
- In URL, paste the arXiv query for LLM/GenAI papers (down below).
- Limited to cs.AI / cs.CL / cs.IR / cs.LG.
- This node fetches the latest ~60 papers; the Code node will then trim the list to the top 5.
We aim for LLM-centric papers (instruction tuning, preference optimization, reasoning, agents, MoE, scaling laws…) and allow RAG/Agentic RAG/Agents to sneak in. Paste this into the RSS Read node:
http://export.arxiv.org/api/query?search_query=(
ti:"large language model" OR abs:"large language model" OR
ti:LLM OR abs:LLM OR
ti:"foundation model" OR abs:"foundation model" OR
ti:"instruction tuning" OR abs:"instruction tuning" OR
ti:"preference optimization" OR abs:"preference optimization" OR
ti:"direct preference optimization" OR abs:"direct preference optimization" OR
ti:DPO OR abs:DPO OR
ti:"reasoning" OR abs:"reasoning" OR
ti:"tool use" OR abs:"tool use" OR
ti:"function calling" OR abs:"function calling" OR
ti:"mixture-of-experts" OR abs:"mixture-of-experts" OR ti:MoE OR abs:MoE OR
ti:"agent" OR abs:"agent" OR ti:"multi-agent" OR abs:"multi-agent" OR
ti:"retrieval-augmented generation" OR abs:"retrieval-augmented generation" OR
ti:"agentic rag" OR abs:"agentic rag"
)
AND (cat:cs.AI OR cat:cs.CL OR cat:cs.IR OR cat:cs.LG)
&max_results=60&sortBy=submittedDate&sortOrder=descending
Step 3. Add Code Node
- Add a Code node.
- Paste in the filtering + scoring code, shared below (LLM topics + optional RAG/Agents).
- This node turns raw RSS items into a neat object.
- This script:
– Normalizes items from arXiv RSS.
– Scores each paper by topic match and recency (short half-life).
– Dedupes by title.
– Picks top 5.
– Builds clean HTML.
– Subjects like LLM weekly: 5 picks.
Paste this into a Code node:
- Language: JavaScript
- Mode: Run once for all items
// --- Config you might tweak ---
const MAX_PICKS = 5;
const RECENT_DAYS = 21; // decays scores beyond this window
const TO_EMAIL = "xyz@gmail.com"; // change if you like
// --- Pull items from previous node (RSS) ---
const raw = $input.all().map(i => i.json);
// --- Normalize ---
const papers = raw.map(e => ({
title: e.title,
url: e.link,
date: new Date(e.isoDate || e.pubDate || e.updated || Date.now()),
summary: (e.contentSnippet || e.content || "").toLowerCase()
}));
// --- Topic lexicon (LLM-first, optional RAG/Agents) ---
const TOPIC_WEIGHTS = [
// core LLM / GenAI
{ re: /\b(llm|large language model|foundation model)s?\b/, w: 3.0 },
{ re: /\b(instruction(-|\s*)tuning|sft|supervised fine(-|\s*)tuning)\b/, w: 2.0 },
{ re: /\b(preference optimization|dpo|ipo|dpo-like|rrhf|orpo)\b/, w: 2.0 },
{ re: /\b(mixture(-|\s*)of(-|\s*)experts|moe)\b/, w: 1.5 },
{ re: /\b(reasoning|chain[-\s]*of[-\s]*thought|cot|program-of-thought)\b/, w: 1.5 },
{ re: /\b(tool[-\s]*use|function[-\s]*calling|api[-\s]*calling)\b/, w: 1.3 },
{ re: /\b(distill(ation)?|knowledge distillation|self[-\s]*play|self[-\s]*correction)\b/, w: 1.0 },
{ re: /\b(scaling laws?|pre[-\s]*training|pretraining|data quality)\b/, w: 1.0 },
// agents (optional but welcome)
{ re: /\b(agentic|agent|multi[-\s]*agent|planner|toolformer|auto[-\s]*gpt)\b/, w: 1.4 },
// retrieval family (optional)
{ re: /\b(retrieval[-\s]*augmented generation|rag|agentic rag)\b/, w: 1.3 }
];
// --- Score by keywords + recency ---
function score(p) {
let s = 0;
const text = `${p.title} ${p.summary}`.toLowerCase();
for (const { re, w } of TOPIC_WEIGHTS) {
if (re.test(text)) s += w;
}
// Recency bonus: within RECENT_DAYS decays linearly to 0
const ageDays = (Date.now() - p.date.getTime()) / 86400000;
if (!isNaN(ageDays)) {
const recency = Math.max(0, (RECENT_DAYS - ageDays) / RECENT_DAYS);
s += 2.5 * recency; // weight recency meaningfully
}
return s;
}
// --- Filter: require at least some LLM/GenAI relevance ---
const MIN_SCORE = 1.5;
let relevant = papers
.map(p => ({ ...p, s: score(p) }))
.filter(p => p.s >= MIN_SCORE);
// --- Deduplicate by normalized title ---
const seen = new Set();
relevant = relevant.filter(p => {
const key = (p.title || "").toLowerCase().replace(/\s+/g, " ").trim();
if (!key || seen.has(key)) return false;
seen.add(key);
return true;
});
// --- Sort by score, then recency ---
relevant.sort((a, b) => (b.s - a.s) || (b.date - a.date));
const top = relevant.slice(0, MAX_PICKS);
// --- Build HTML email ---
const rows = top.map((p, i) => `
<tr>
<td style="vertical-align:top;padding:8px 0;"><b>${i + 1}.</b></td>
<td style="padding:8px 0;">
<div style="font-size:15px;line-height:1.3;"><a href="${p.url}">${p.title}</a></div>
<div style="color:#555;font-size:13px;margin-top:2px;">
${isNaN(p.date) ? "" : p.date.toISOString().slice(0,10)} • arXiv
</div>
</td>
</tr>`).join("");
const html = `
<div style="font-family:system-ui,-apple-system,Segoe UI,Roboto,Arial,sans-serif;">
<h2 style="margin-bottom:6px;">LLM Weekly — Top ${top.length}</h2>
<div style="color:#666;font-size:13px;margin-bottom:10px;">
Curated by n8n Cloud • ${new Date().toLocaleString('en-GB', { timeZone: 'Europe/Helsinki' })}
</div>
<table width="100%" cellpadding="0" cellspacing="0">${rows || "<tr><td>No strong matches this run.</td></tr>"}</table>
<div style="color:#888;font-size:12px;margin-top:12px;">
Focus: Generative AI & LLMs (instruction tuning, preference optimization, reasoning, MoE, tool use, agents).
Bonus: RAG / Agentic RAG / Multi-Agent if present.
</div>
</div>`;
return [{ json: { to: TO_EMAIL, subject: `LLM weekly: ${top.length} picks`, html, empty: top.length === 0 } }];
Step 4. Add Gmail — Send Message
Add a Gmail node → Send a message.
Connect your Gmail account with OAuth.
Configure:
– To: your address (e.g xyz@gmail.com)
– Subject: = {{$json.subject}}
– Message: = {{$json.html}}
– Email type: HTML
Final Connections
Connect them in order: Schedule Trigger → RSS Feed Read → Code → Gmail
Once this is done:
- Manually run the workflow once (to test).
- Check that the Gmail node actually sends you an email.
- Activate the workflow.
💥 This takes an afternoon, then quietly pays you back every week. The inbox version of a research assistant: no drama, no meetings, just results.
